Tfrecords and TFRecordDataset. Your friends to performance data access on Google Cloud ML

TensorFlow is an awesome framework where deploy deeplearning. Actually i’m working very hard on it and exploring all benefits and powerful. Then i started to deploy the models on Google Cloud. Google cloud is an awesome cloud solution where there are multiple services for all clouds needs. One of its tools very important for Deep Learning developers is Google Cloud Machine Learning that allow train our models very cheaper in high performance computers.
Then i put my hands to work on. As a computer vision developer i create my CSV file that store all file image uris and the class for each one. And following the tutorials, first i deploy and test the algorithm locally. All works fine and in few minutes i get the results. Then i started to deploy on the cloud and i upload all my png files and the CSV file for train and test to Google Storage.
After finish to upload my 60k images for training and 10k for test from MNIST to google storage, i execute with the simple command line that google provide my tensorflow python scripts, tested locally. After wait more than 20 minutes i knew that something wrong is happening. Why locally with a laptop in few minutes i had results and in a powerful machine on google cloud was not working? Then i asked to me what could be the main issues:
- The Google Storage is in other region of my Google ML.
- I have some issue on my code
After check that the google storage and google ML are on same region and are correctly setup and my code is fine the i start to be crazy…. What happens? Why it’s so slow to give me some output?.

Then i start to debug… Any TensorFlow developer knows that debug on it is very complex and dificult then i thought that TensorFlow and Google can think on this and give some tool to inspect the performance of a TensorFlow code and… BANG there is a function to do it. My new friend is called ProfilerHook. And adding the small snippet of code to my code
profiler_hook = hooks.ProfilerHook(save_steps=10, output_dir=args.job_dir)
classifier.train(input_fn=model.data_train_estimator, steps=20000, hooks=[profiler_hook])First i test locally and get the first results and explore with chrome://tracing. All seems fine. Then upload to Google Cloud ML and wait, wait… and i have the first log on my google storage from profiler… and open it side by side to my local profiler to compare… See image to see the results:
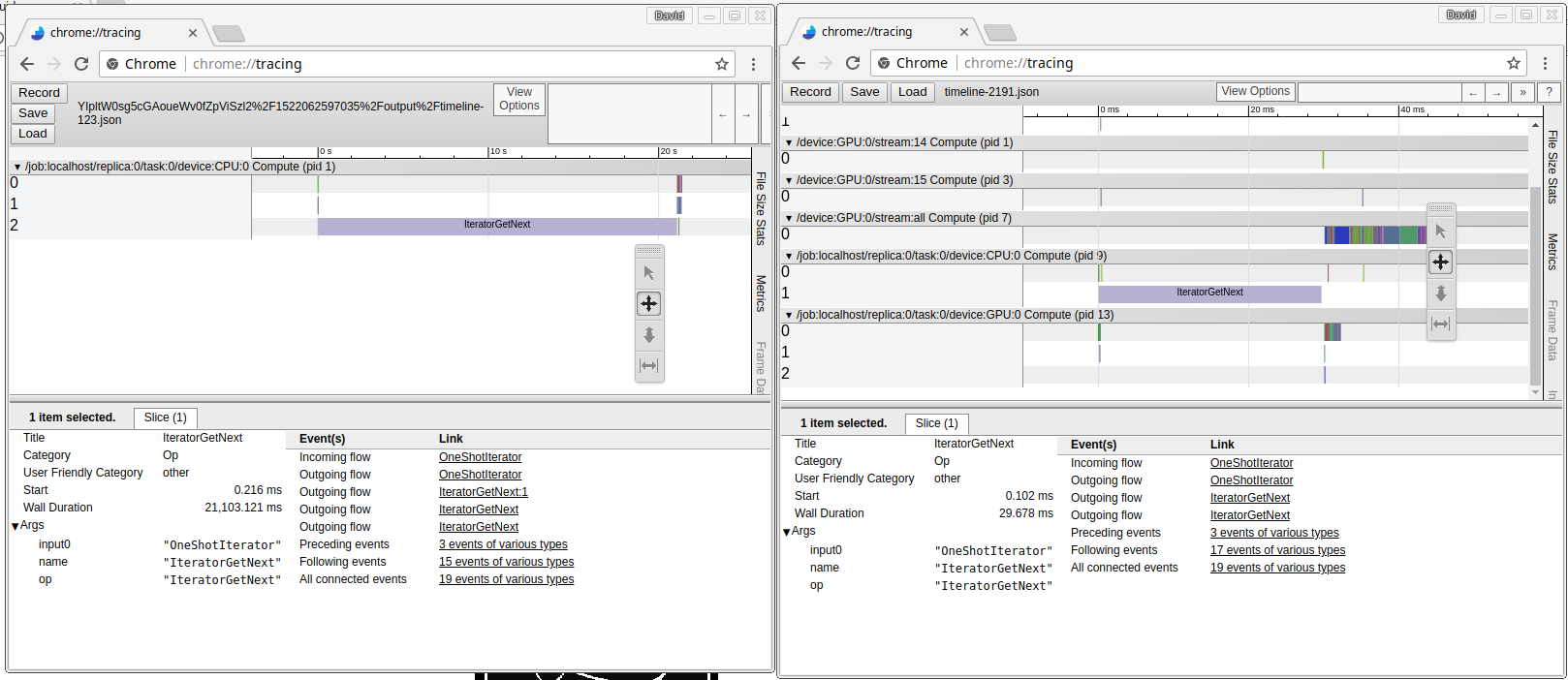
Oh my God! My local version execute the iteratorGetNext in 29ms and in google cloud is 21.103ms 20seconds!! one step batch 20 seconds. I set around 20000 steps or epochs to train, this means that in my local version tooks around 10min to get all batchs plus process the training, around 15minuts to get the result, something reasonable. But in google cloud tooks around 111hours!!!! only get the batchs…
The issue then is the access to each image to google storage, that tooks around 500ms each one to open put on memory and close…. Then, what could be the solutions? Don’t access to google storate so many times to access to data.Then we can convert our big amount of files in one single file using nunpy single file, that could be a solution or use the tfrecord and load using tfrecorddataset and avoid to use a third dependency if it’s not required.
I search on google how to convert a CSV file with filename and class to tfrecord file and finally i create my own:
import tensorflow as tf
import pandas as pd
from IPython.display import clear_output
def _bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
def _int64_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
def create_tfrecords_from_csv(csv_file, output_file):
tfrecords_filename = output_file
writer = tf.python_io.TFRecordWriter(tfrecords_filename)
csv_file_records= pd.read_csv(csv_file, header=None, names=['file', 'class'])
total_rows= csv_file_records['class'].count()
for index, row in csv_file_records.iterrows():
clear_output(wait=True)
print index, 'of', total_rows
label= row['class']
img= io.imread(row['file'])
h= img.shape[0]
w= img.shape[1]
img_raw= img.tostring()
example= tf.train.Example(features= tf.train.Features(feature={
'label': _int64_feature(label),
'height': _int64_feature(h),
'width': _int64_feature(w),
'image_raw': _bytes_feature(img_raw)
}))
writer.write(example.SerializeToString())
writer.close()
create_tfrecords_from_csv('train.csv', 'train.tfrecords')After execute the script locally and convert all my images dataset in one single file train.tfrecords i upload the file to google storage and execute and evaluate the performance and get the following result:
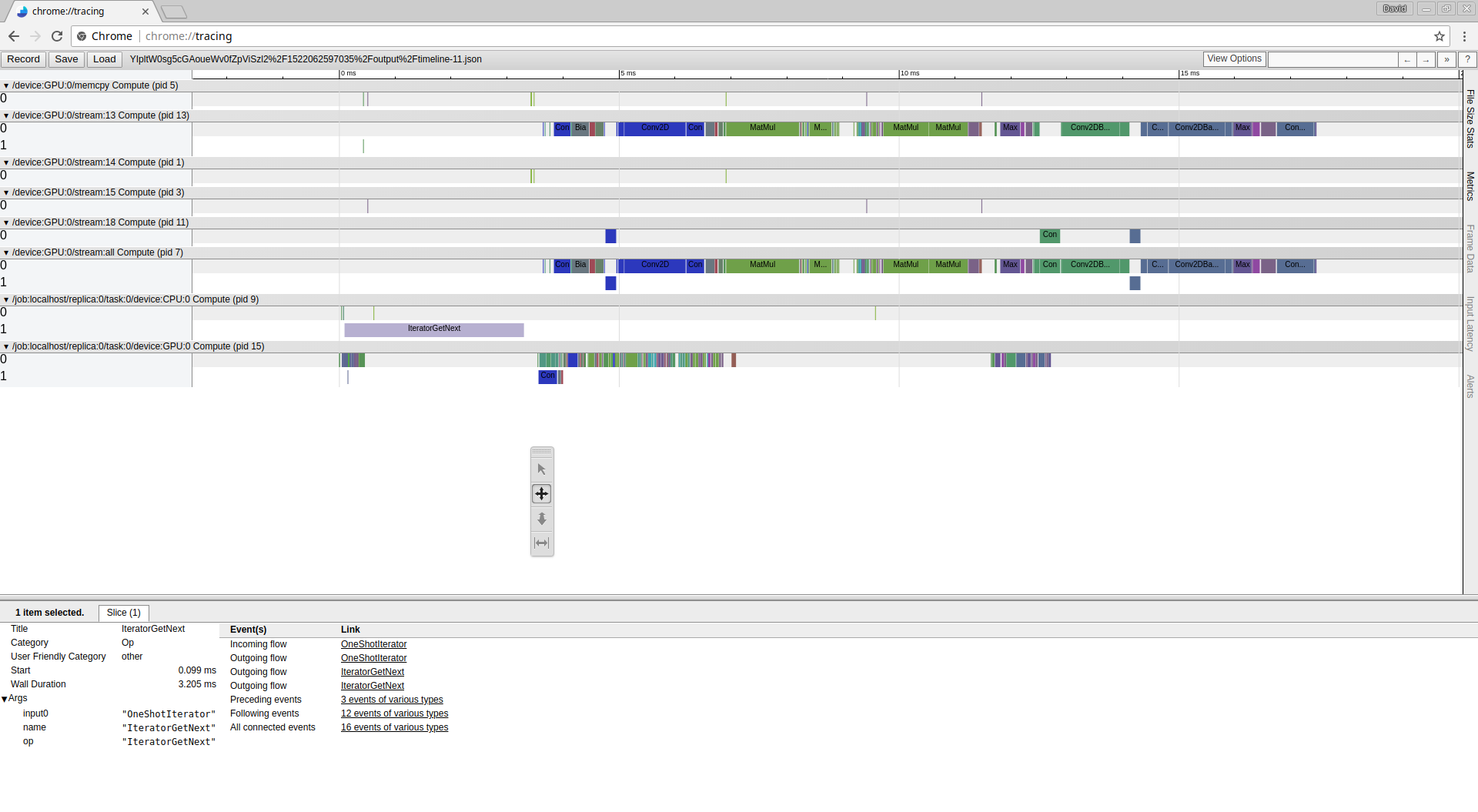
Awesome now it’s very fast, and as i expected more fast than access to thousand files locally, now it’s only 3ms every iterator, more less than the 20seconds and more less than local storage SSD that whas 29ms. It’s 10x more fast than SSD disk and more than 6000x on GS.